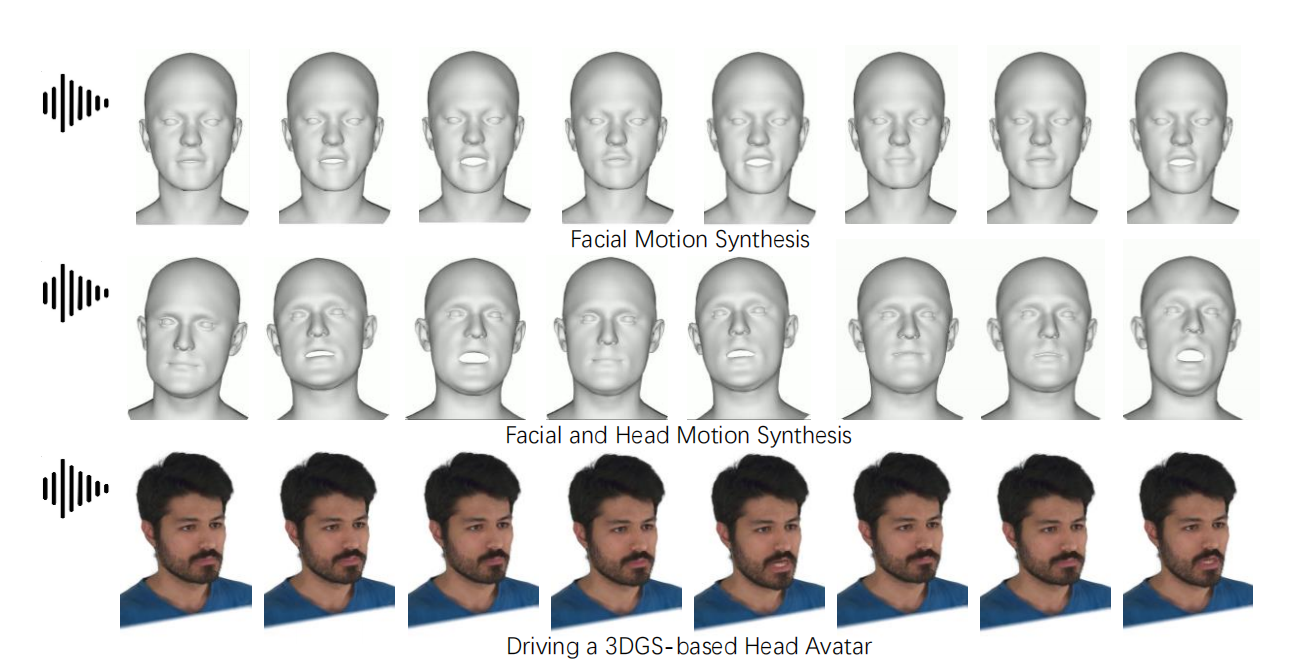
Fig. 1: Given a speech audio, our method can synthesize facial motion, head motion and drive a 3D Gaussian Splatting based head avatar.
Abstract
The speech-driven facial animation technology is generally categorized into two main types: 3D and 2D talking face. Both of these have garnered considerable research attention in recent years. However, to our knowledge, the research into 3D talking face has not progressed as deeply as that of 2D talking face, particularly in terms of lip-sync and perceptual mouth movements. The lip-sync necessitates an impeccable synchronization between mouth motion and speech audio. The speech perception derived from the perceptual mouth movements should resemble that of the driving audio.
To mind the gap between the two sub-fields, we propose Learn2Talk, a learning framework that enhances 3D talking face network by integrating two key insights from the field of 2D talking face. Firstly, drawing inspiration from the audio-video sync network, we develop a 3D sync-lip expert model for the pursuit of lip-sync between audio and 3D facial motions. Secondly, we utilize a teacher model, carefully chosen from among 2D talking face methods, to guide the training of the audio-to-3D motions regression network, thereby increasing the accuracy of 3D vertex movements.
Extensive experiments demonstrate the superiority of our proposed framework over state-of-the-art methods in terms of lip-sync, vertex accuracy and perceptual movements. Finally, we showcase two applications of our framework: audio-visual speech recognition and speech-driven 3D Gaussian Splatting-based avatar animation.
Video
Due to video compression, the online video contains some artifacts in lip-sync. For better audio-visual experience, please download the high definition video.
Qualitative Evaluation
We visually compare our method with the competitors. We illustrate six typical frames of synthesized facial animations that speak at specific syllables. Compared with the competitors, the lip movements produced by Learn2Talk are more accurately articulated with the speech signals and also more consistent with the reference.
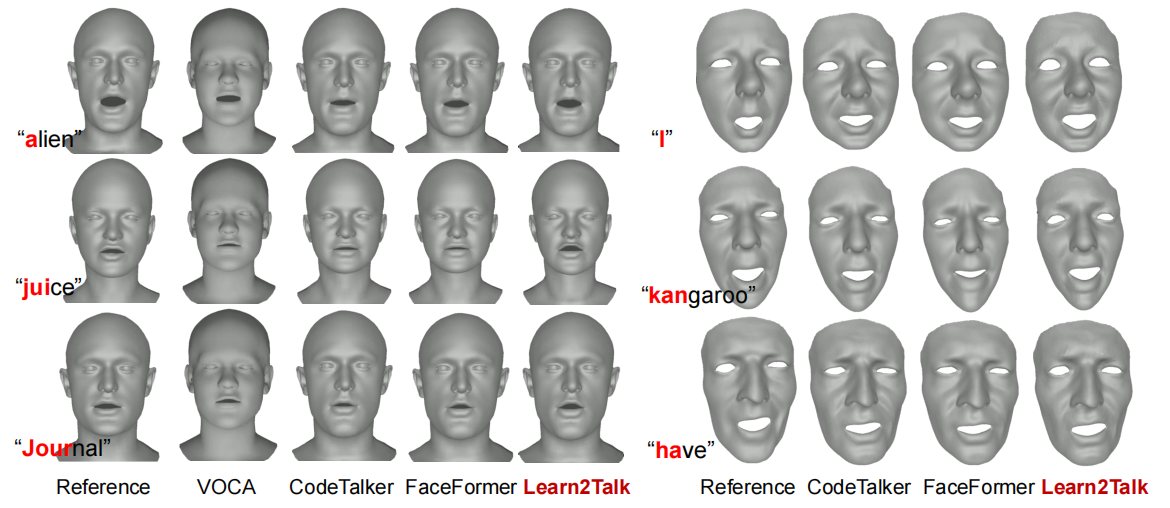
Fig. 2: Visual comparisons of sampled facial motions animated by different methods on VOCA-Test (left) and BIWI-Test-A (right).
Fig. 3 shows the 3D reconstruction error heatmaps of the sampled frames, produced by the four methods. The per-vertex errors are color-coded on the reconstructed mesh for visualization. It could be observed that, our method obtains more accurate vertices both in mouth region and upper-face region.
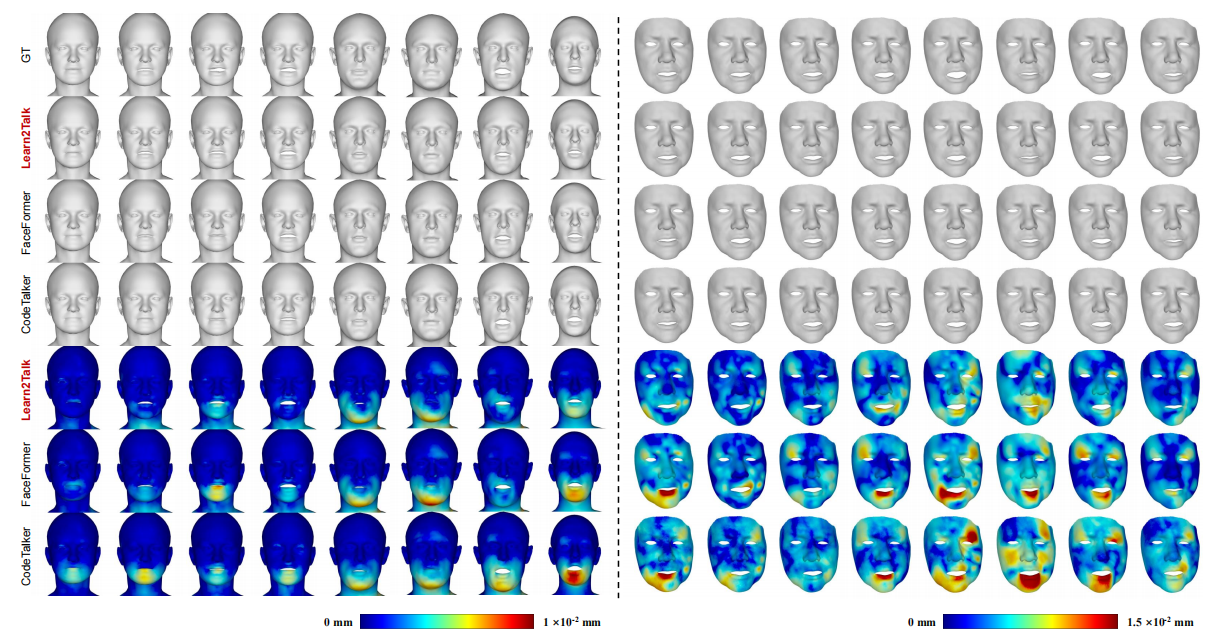
Fig. 3: 3D reconstruction error heatmaps of sampled facial motions predicted by different methods on VOCA-Test (left) and BIWI-Test-A (right).
Fig. 4 shows the visual comparisons on other languages, including Chinese, Japanese and Korean. Although trained on English datasets, our method can generalize well to any other language. This is because that our method uses the signal characteristics of the speech audio, instead of words or linguistics. From Fig. 4, it could be observed that our method generates more expressive animation, with obvious movements in opening mouth, pouting and closing mouth. The comparisons on facial animations with all frames are available in the supplementary material.

Fig. 4: Visual comparisons of sampled facial motions predicted by different methods across languages, including Chinese, Japanese and Korean.
Applications
Audio-visual speech recognition. The first application is to synthesize the audio-visual data for the task of the audio-visual speech recognition. We use Learn2Talk to synthesize the video clips from the audios on the subset of LRS3, and then construct the labeled audio-visual corpora which can be used to train and test the audio-visual speech recognition network. Such synthesized audio-visual data is valuable in labeled data augmentation and personal privacy protection.
Speech-driven 3DGS-based avatar animation. The recent 3DGS method achieves high rendering quality for novel-view synthesis with real-time performance. Instead of training the neutral network in 3D space such as NeRF, it optimizes the discrete geometric primitives, namely 3D Gaussians. 3DGS has already been used to reconstruct the head avatar, and the human body avatar from multiple view images. The second application of our method is that, it enables the speech-driven 3DGS-based head avatar. Our speech-driven 3DGS animation is well in-sync with the driving audio, and supports multiple view synthesis in each frame.

Fig. 5: Visualization of the sampled motions of the speech-driven 3DGS-based head avatar. In each frame, we show the FLAME model generated by our method (1st row-left), and the front view (1st row-right), two side views (2nd row) of the driven avatar.